

The challenge with Web3 analytics
The challenge with Web3 analytics
Web3 decentralization makes it hard to track user behavior and power scalable product and marketing decisions.

This is a two-part series written for Third Academy navigating the data analytics differences in Web2 vs. Web3.
In part I, I dive into how Web3 is charting new challenges for operators who need to learn from customer data. Part II and Part III cover respectively which metrics should operators track in Web3, and which stacks are emerging to help them carry out the job.
Follow me and Third Academy to get all these updates — and more — in your inbox.

Web3 scales data fragmentation
If you’re part of a startup team, you often rely on data to inform your decisions. That’s data analytics — making decisions based on insights contained in data, such as how your customers interact with your marketing channels, websites, and apps.
Analytics are critical to any aspect of the business; not only do they help you learn what your customers are doing with your products so you can better serve their needs, but they can also make (or break) multi-billion dollar businesses.
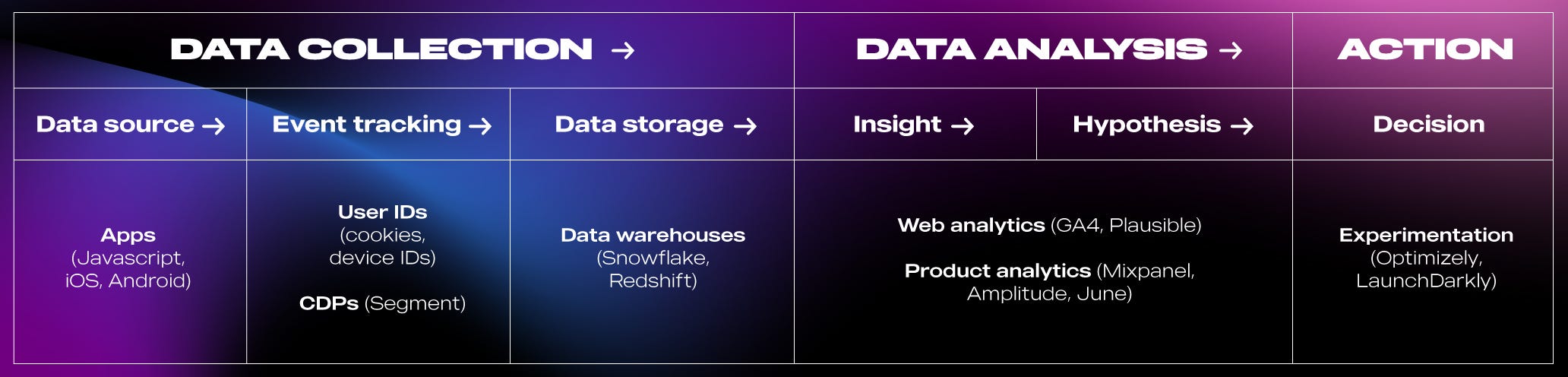
Because of how critical analytics are, startups can rely on world-class literature and product stacks to make data-driven decisions — Segment, GA, Mixpanel, Amplitude, and June become your bread and butter. Thanks to these tools, you can track things like signups, daily active users (DAUs), or customer acquisition cost (CAC), predict churn, forecast revenue, or attribute marketing spending.
But when you’re building a Web3 product, even data analytics enter unchartered territory:
Decentralization fragments customer identities across multiple wallets and chains, making it challenging to collect accurate data and understand customer behavior. Also, Web3 applications (still) run on Web2 interfaces, which adds to the fragmentation and hinders accuracy. How to unify this data to enable accurate attribution and personalization?
DeFi, NFTs, and DAOs are introducing new metrics like TVL, floor price, community engagement, and more. Among them, which ones are actually important to track and analyze for startup operators — and what are the related formulas — in order to get the feedback they need to build better products?
New, hybrid data stacks will be required to unify data fragmented across Web3, trace it back to Web2, and have an accurate picture of customer profiles — all while preserving their privacy. What do these stacks look like, and what are the new categories of SaaS analytics, and their emerging leaders?
In this post, we’ll dive into the first point. Subscribe to get the following articles straight in your inbox.
The challenge of data fragmentation
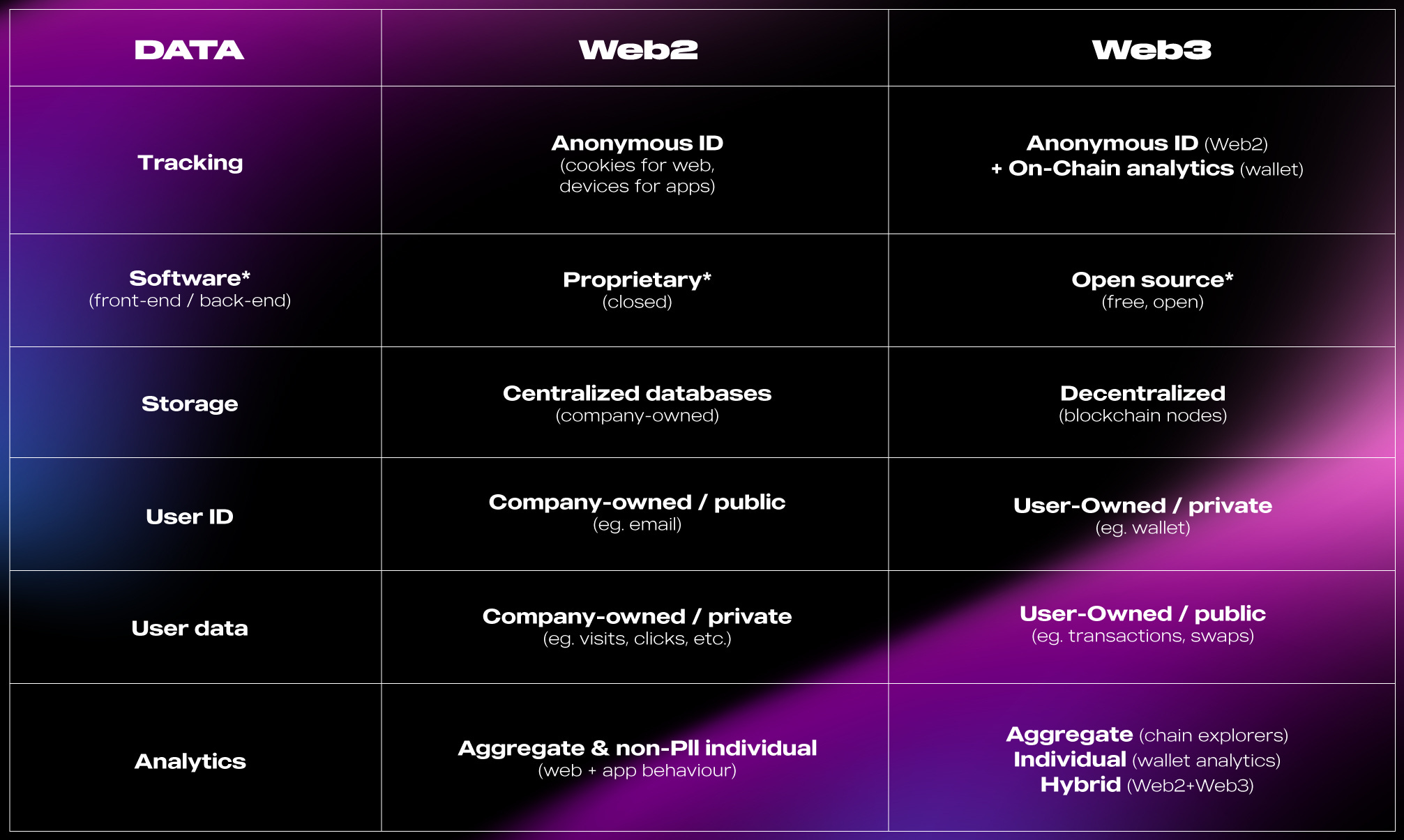
In Web2, teams use cookies and device IDs to collect data. These enable personalized product experiences and targeted promotions via retargeting ads. But as privacy concerns grow with GDPR and CCPA, even Apple and Google announced plans to phase out third-party cookies, opening up new challenges for data collection. This had a serious impact on large advertising publishers, which now have a much harder time gathering intent (eg. browsing habits and history) or location data (eg. IP address).
The Web3 ethos of decentralization further builds on this narrative, voicing privacy concerns, especially given recent episodes of censorship. On the other hand, Web3 adds complexity to tracking accurate customer behavior — making things like attribution and personalization much, much harder for product and marketing teams. Let’s unpack how
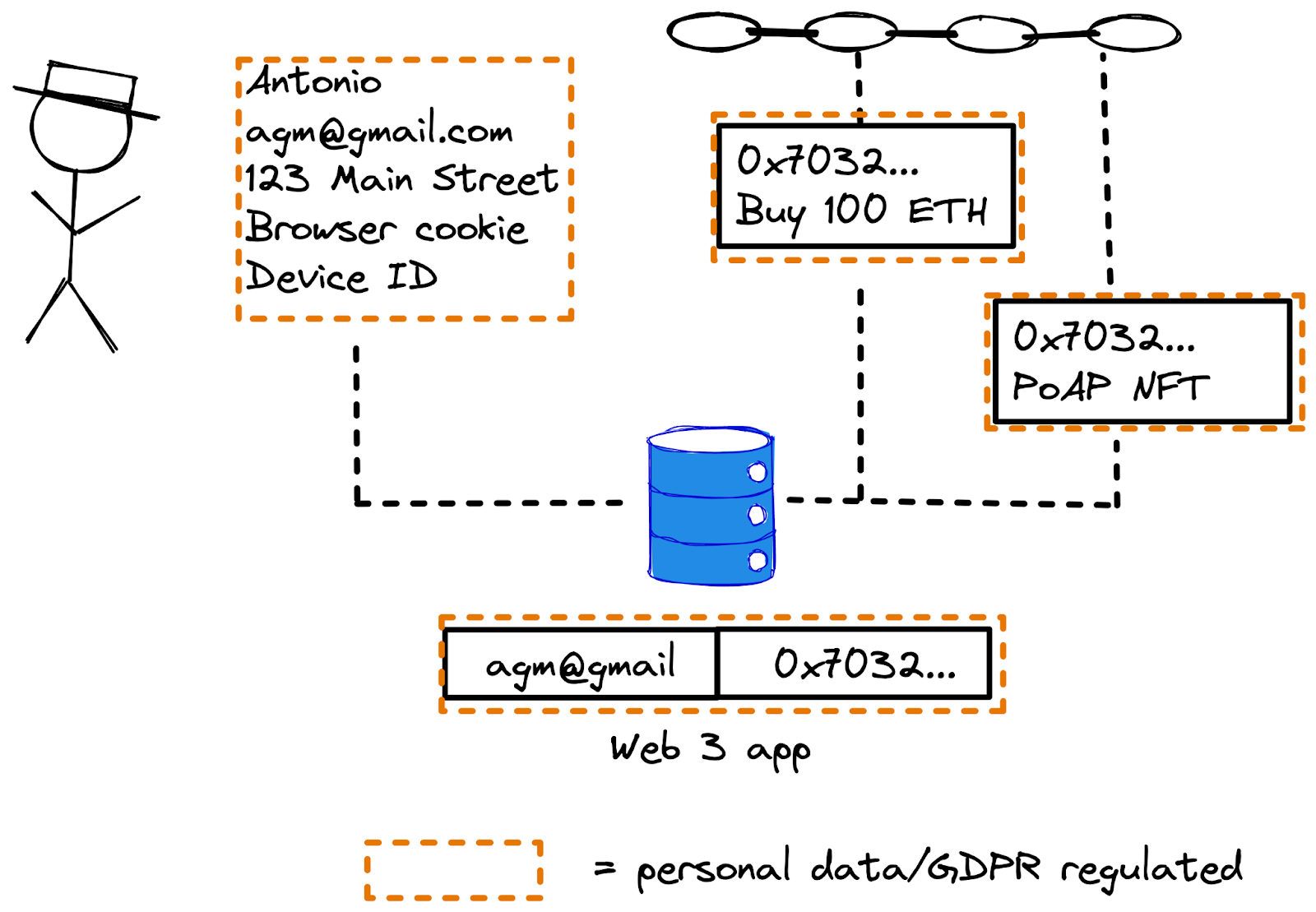
When you buy something online, Amazon uses cookies to track all your clicks across their sites, and device IDs to track clicks across their apps, and links them both back to a unique user ID related to your Amazon account. This makes it easy to gather behavioral data and give you personalized suggestions or drive product decisions.

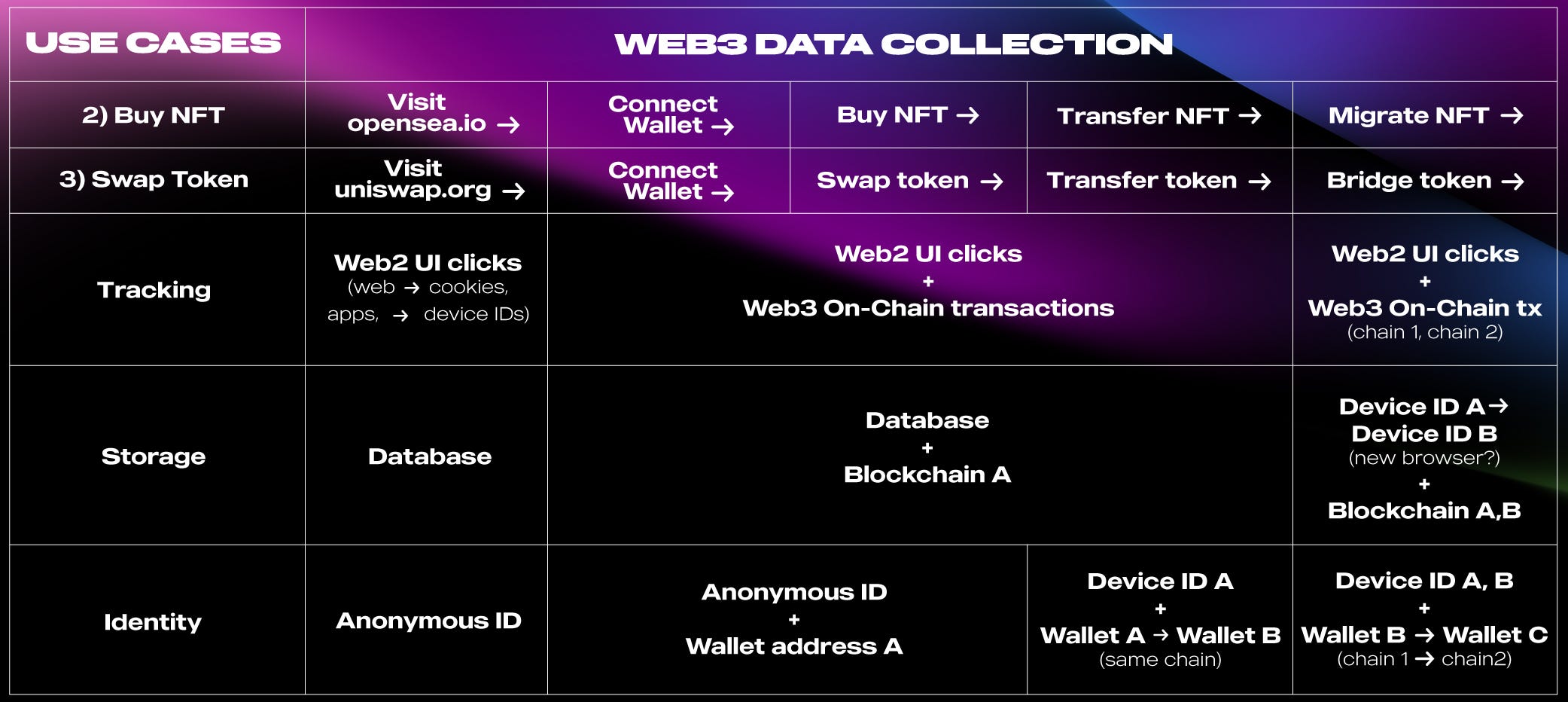
However, when you buy an NFT on OpenSea, or swap tokens on UniSwap, both of these have a much harder time linking your behavior to your identity. This is due to two things: identity and interface fragmentation. Let’s understand each in more detail.
Identity fragmentation
In Web 3, transaction data is public on the blockchain, but identity can be kept private. In Web2, it’s the opposite (user identifiers — like email — are public, but transaction data are expected to be kept private, mostly because they’re financial information).
No KYC, no identity. Decentralized, permissionless apps, like OpenSea or UniSwap, don’t require KYC forms; the Web3 ethos of ownership applies also to data — they don’t store ‘accounts’ that they can link to your in-app behavior.
Decentralized wallet, decentralized identity. Wallet addresses contain only behavioral data — eg. transactions, amounts, and other metadata — which is publicly available and immutable on the blockchain. Unless you publicly link this to your identity — eg. by connecting your Twitter to OpenSea— this design keeps behavior intrinsically separate from identity.
Multiple wallets, multiple identities. Users can also set up different wallets for different use cases — for example, one to store NFTs and one to store tokens — which allow them to multiply their identity (and skew your numbers) ad infinitum, making it extremely difficult to reconcile a set of actions to one identity (for now, until we develop accurate AI behavioral analytics).
Identity fragmentation poses two fundamental challenges:
Unification & reconciliation. How can we unify data from multiple decentralized wallets to keep customer data accurate and have a better understanding of user acquisition, attribution, and retention? (This problem already existed in Web2 — think attributing actions to people with 5+ devices — but it could become much greater as identity fragmentation scales with Web3 adoption.)
Privacy integrity. Let’s say you can solve the above with a join between Web2 identity (public email) and Web3 engagement (eg. transactions) — which still requires an opt-in from the user — and run cross-matching models (eg. by matching two wallets to one device) to reconcile multiple wallets to one identity. How can we then ensure the Web3 ethos of decentralization, ownership, and ‘contextual privacy’ remains intact? Without making decentralized protocols like UniSwap formally data controllers, and hence requiring GDPR compliance?
Interface fragmentation
I know things are getting convoluted, but that’s why it’s important to unpack them in detail.
Web2 front-end, Web3 back-end. To date, most Web3 dApps still run on Web2 websites and interfaces. This means that whether the back-end runs on decentralized blockchains, the front-end of the application still runs on traditional Web2 sites. This disconnect makes it even harder to reconcile actions done on Web2 UIs (eg. clicks, page visits, etc.) with on-chain ones (eg. transactions, swaps, transfers, etc.), and trace them both back to one, single identity (eg. wallet address).


Web3 vs. Web2 data. On the flip side, not all engagement data happens on Web3 either. Teams that focus on tracking only things that happen on-chain or on Web3 products will miss out on building a complete picture of their customers, and all the stuff they do on Web2 (eg. what they buy on Amazon, which movies they stream on Netflix, etc.).
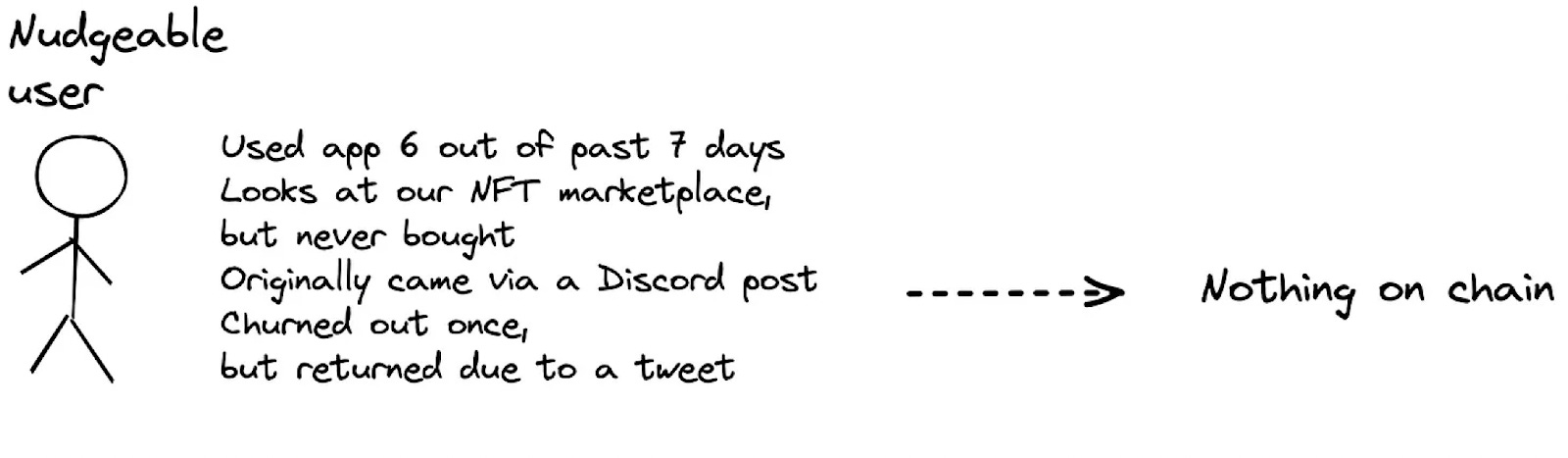
Cross-chain transactions. Cross-chain transactions — for example, bridging tokens between Ethereum and Solana — further scale the interface fragmentation by adding an additional back-end to the mix, and adding more complexity for reconciliation.
Interface fragmentation reinforces the unification/reconciliation challenge (and the privacy integrity challenge as a result):
How can we trace back interactions from a centrally hosted front-end (eg. UniSwap website) to interactions hosted by a decentralized back-end (eg. Uniswap open-source smart contracts) in a way that’s aligned with the Web3 ethos of data ownership? (Cough, zero-knowledge proofs?)
How can we harmonize various blockchain standards (eg. Ethereum and Solana) to normalize its data, similarly to what Segment Customer Data Platform does with its various sources and destinations, to keep data clean and flowing across different environments?
These are just some questions I’d love to find answers to. I’m excited about:
How (soulbound) NFTs could help store engagement data in Web3 wallets without the need for organizations to use cookies or device IDs to collect data, as users can just connect their wallets to unlock personalized web and app experiences. This could enable personalization — and even power more accurate attribution —
How zero-knowledge proof can enhance the contextual privacy layer to share specific attestation and data with organizations without revealing the actual user identity.
This could solve some identity and interface fragmentation while enabling data ownership in conjunction. Even if we’re not there yet.
To summarize, we’ve seen how:
Data analytics is a mission-critical function in any organization — Web2 or Web3 — that powers scalable product and marketing decisions, like personalization or attribution.
Web3 decentralization is making it technically challenging to enable these use cases, while at the same time preserving the contextual privacy of users, based on the new ethos of data ownership.
The progressive fragmentation of Web2 and Web3 calls for a convergence of these standards that is interoperable — re-bundling user identity and data together while preserving privacy. I think — because Web2 and Web3 user experiences will co-live for quite a long period of time — the data stacks that will emerge to solve the data fragmentation challenge will be hybrid, and interoperable, and not necessarily Web3 native.
In the next articles, we’ll explore which new metrics are emerging with Web3, and which data stacks are needed to solve these challenges.
Shoutout to Leo Ubbiali, Vladimir Oustinov, Chris Sotraditis, David Lumley, and Kameron Tanseli for reviewing this content and providing their thoughtful feedback.
Follow Matteo and Third Academy to get all these updates — and more — in your inbox.